Introduction: What Are Generators and Why Should You Care?
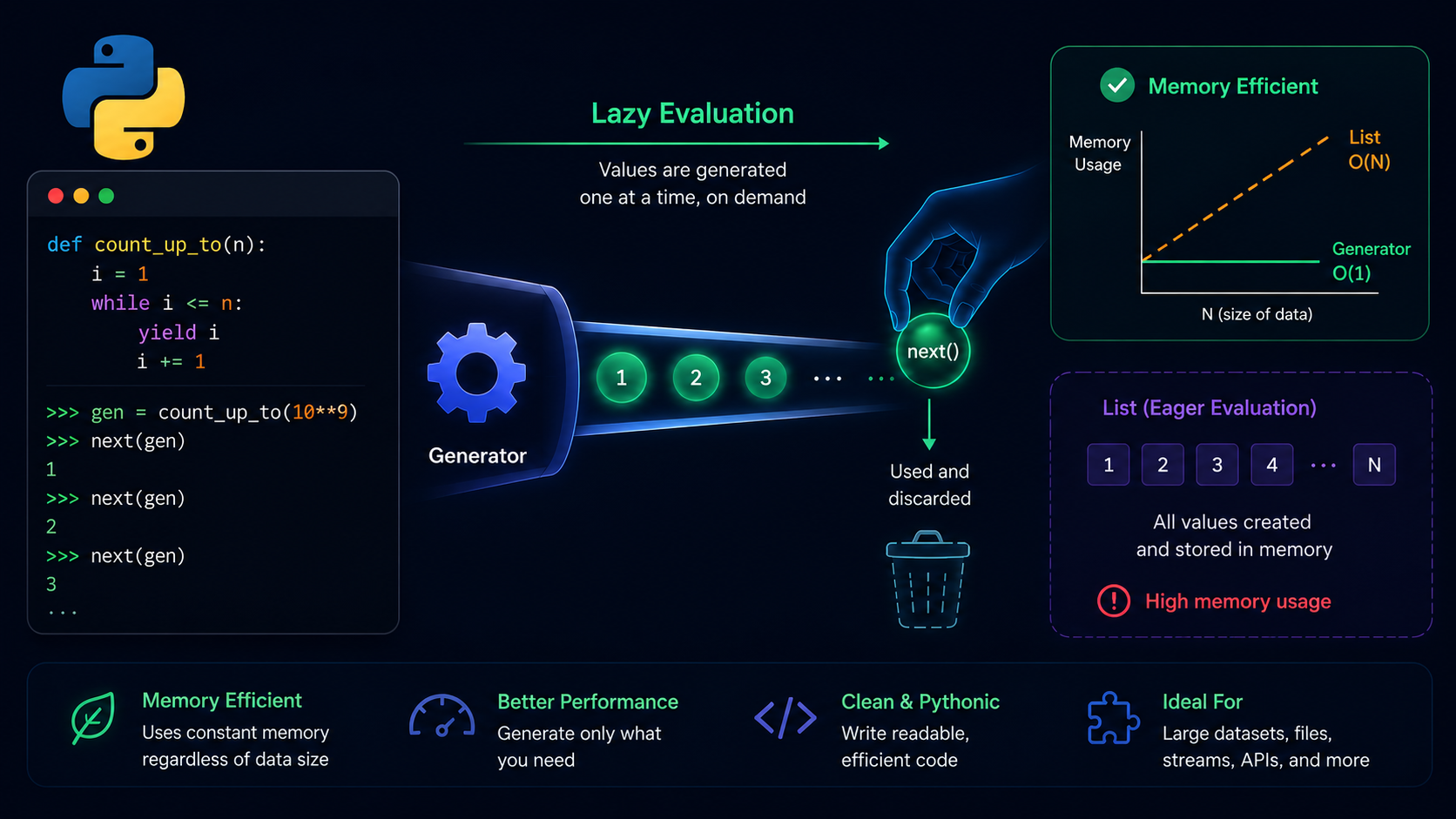
At their core, generators are a special class of functions in Python that produce a sequence of values lazily—one at a time, on demand—rather than computing and storing all values in memory simultaneously. They achieve this through the yield keyword, which suspends the function’s execution state and returns a value to the caller, resuming exactly where it left off when the next value is requested.
If you’ve ever worked with large datasets, streaming data, or computationally expensive sequences, you’ve likely hit the memory constraints that conventional collections impose. A standard list comprehension like [x**2 for x in range(10_000_000)] allocates memory for all ten million results at once. A generator sidesteps this entirely.
The Core Mechanism
A generator function looks almost identical to a regular function, with one critical difference: it uses yield instead of (or in addition to) return. When Python encounters yield, it doesn’t terminate the function. Instead, it freezes the function’s local state—variables, instruction pointer, and stack frame—and hands control back to the caller.
def square_sequence(n):
for i in range(n):
yield i ** 2Calling square_sequence(5) doesn’t execute the function body. It returns a generator object—an iterator that conforms to Python’s iteration protocol (__iter__ and __next__). Values materialize only when you iterate:
gen = square_sequence(5)
print(gen) # <generator object square_sequence at 0x7f...>
for value in gen:
print(value) # 0, 1, 4, 9, 16Python also supports generator expressions, which provide a concise syntax analogous to list comprehensions but wrapped in parentheses rather than brackets:
squares = (x ** 2 for x in range(5))This produces the same lazy evaluation behavior without defining a named function.
Why You Should Care
Generators matter for three practical reasons:
- Memory efficiency — They produce items one at a time, maintaining O(1) memory overhead regardless of sequence length.
- Representation of infinite sequences — Because no collection is pre-allocated, generators can model unbounded streams (e.g., sensor readings, event logs, or mathematical sequences) without exhausting system memory.
- Composability — Generators chain naturally into data pipelines, where each stage pulls from the previous one, enabling clean separation of transformation and filtering logic.
For software engineers building production systems and researchers processing large corpora, generators offer a mechanism to write code that scales gracefully. The sections that follow dissect their internal mechanics, demonstrate advanced patterns, and illustrate where they deliver the most significant performance gains.
Understanding Iterators: The Foundation of Generators
Before you can truly grasp how generators work, you need to understand the iterator protocol—the mechanism that underpins all iteration in Python.
The Iterator Protocol
An iterator is any object that implements two special methods: __iter__() and __next__(). Together, these methods define a contract: the object can be iterated over, producing one element at a time until it raises a StopIteration exception to signal exhaustion. Every for loop you write relies on this protocol behind the scenes.
Here’s what happens when Python encounters a for loop:
- Python calls
iter()on the iterable to obtain an iterator object. - It repeatedly calls
next()on that iterator to retrieve successive values. - When
next()raisesStopIteration, the loop terminates.
# Manual iteration demonstrating the iterator protocol
numbers = [10, 20, 30]
iterator = iter(numbers)
print(next(iterator)) # 10
print(next(iterator)) # 20
print(next(iterator)) # 30
print(next(iterator)) # Raises StopIterationBuilding a Custom Iterator
To appreciate what generators simplify, examine the boilerplate required to build an iterator from scratch:
class CountUp:
def __init__(self, start, end):
self.current = start
self.end = end
def __iter__(self):
return self
def __next__(self):
if self.current >= self.end:
raise StopIteration
value = self.current
self.current += 1
return value
for num in CountUp(1, 4):
print(num) # 1, 2, 3This works, but it demands explicit state management—you must track self.current, define the termination condition, and manually raise StopIteration. For simple sequences, this is verbose and error-prone.
Why This Matters for Generators
Generators exist precisely to eliminate this ceremony. A generator function automatically implements the iterator protocol. When Python encounters a yield statement, it pauses the function, saves its entire execution state—local variables, instruction pointer, call stack—and returns the yielded value to the caller. On the next call to next(), execution resumes exactly where it left off.
This means you get lazy evaluation for free. Values are produced one at a time, on demand, rather than being materialized into a complete collection in memory. When you print a generator object directly, you won’t see data—only a reference like <generator object at 0x7f007ac5d080>—because the values haven’t been computed yet.
Understanding the iterator protocol gives you a mental model for everything generators do: they are a syntactically elegant, memory-efficient way to produce iterators without writing classes. With this foundation in place, the yield keyword becomes intuitive rather than magical.
Creating Generators: How the yield Keyword Pauses and Resumes Execution
Now that you understand the iterator protocol, let’s examine how yield actually works. When you define a function using yield instead of return, Python transforms it into a generator function. The critical distinction lies in execution behavior: a regular function runs to completion and returns a single value, while a generator function pauses at each yield statement, saves its entire execution state, and resumes exactly where it left off when the caller requests the next value.
The Mechanics of yield
Whenever the interpreter encounters a yield statement, the function emits the yielded value to the caller, then freezes. Local variables, the instruction pointer, and the call stack all persist in memory. Execution only resumes when next() is called on the generator object—or when a for loop implicitly requests the next iteration.
Consider this example:
def countdown(n):
print("Starting countdown")
while n > 0:
yield n
n -= 1
print("Countdown complete")
gen = countdown(3)
print(next(gen)) # prints "Starting countdown", then 3
print(next(gen)) # prints 2
print(next(gen)) # prints 1
print(next(gen)) # prints "Countdown complete", then raises StopIteration
Calling countdown(3) does not execute the function body. It returns a generator object. Only when you invoke next(gen) does execution begin—running until the first yield, returning 3, and suspending. Each subsequent next() call resumes from the exact point of suspension, restoring the local variable n to its previous state.
State Preservation Without Boilerplate
This pause-and-resume mechanism eliminates the need to manually track iteration state in a class. Compare this to the CountUp iterator from the previous section: no __iter__, no __next__, no self.current. The yield keyword encapsulates all of that bookkeeping implicitly.
Infinite Sequences
Because generators produce values lazily, they can represent unbounded sequences without allocating memory for all elements:
def infinite_sequence():
num = 0
while True:
yield num
num += 1
gen = infinite_sequence()
print(next(gen)) # 0
print(next(gen)) # 1
# Continues indefinitely on demandNo list of infinite length exists in memory—only the current state of num persists between calls.
Termination and StopIteration
When a generator function’s code path reaches the end of the function body (or an explicit return statement without a value), Python automatically raises a StopIteration exception. This signals to iteration constructs like for loops that no more values are available, following the standard iterator protocol.
Understanding this pause-resume lifecycle is foundational. It explains why generators consume minimal memory, why they integrate seamlessly with for loops, and why they serve as the building blocks for more advanced patterns like coroutines and data pipelines.
Generator Expressions: A Concise, Memory-Efficient Alternative to List Comprehensions
If you’ve written list comprehensions in Python, you already know the syntax for generator expressions—just swap the square brackets for parentheses. This small change has significant implications for memory usage and performance.
A list comprehension eagerly constructs the entire list in memory. A generator expression produces values lazily, one at a time, only when requested:
# List comprehension — stores all values in memory
squares_list = [x ** 2 for x in range(1_000_000)]
# Generator expression — produces values on demand
squares_gen = (x ** 2 for x in range(1_000_000))
The list variant allocates memory for one million integers immediately. The generator variant allocates memory for only a single value at any given point during iteration.
Anatomy of a Generator Expression
The general form mirrors a list comprehension:
(expression for item in iterable if condition)When you assign a generator expression to a variable and inspect it, Python does not display the contained data. Instead, it returns a generator object reference:
>>> squares = (x ** 2 for x in range(5))
>>> print(squares)
<generator object <genexpr> at 0x102e3acf0>To retrieve values, you must iterate—either with a for loop, next(), or by passing the generator to a consuming function:
for square in squares:
print(square)
# Output: 0, 1, 4, 9, 16When to Prefer Generator Expressions
Use generator expressions when you need to:
- Process large datasets where holding all elements in memory is impractical.
- Feed data into aggregate functions like
sum(),max(), ormin()that consume iterables without needing a materialized list. - Chain processing steps in a pipeline where intermediate collections would waste memory.
Consider summing squares of the first ten million integers:
# Memory-intensive approach
total = sum([x ** 2 for x in range(10_000_000)])
# Memory-efficient approach
total = sum(x ** 2 for x in range(10_000_000))
In the second form, Python never builds a ten-million-element list. It feeds each squared value directly into sum(), keeping memory consumption nearly constant regardless of the range size.
Key Limitations
Generator expressions are single-use. Once exhausted, they produce no further values. If you need to iterate multiple times over the same data, either recreate the generator or use a list. Additionally, generators do not support indexing or slicing—random access requires a sequence type.
Understanding when to reach for a generator expression versus a list comprehension is a practical skill that directly impacts the scalability of your code. For any operation where you consume elements sequentially and don’t need the full collection afterward, the generator expression is the more disciplined choice.
Practical Use Cases: Infinite Sequences, Data Pipelines, and Large Dataset Processing
With the mechanics covered, let’s turn to real-world scenarios where generators deliver tangible benefits. The following three patterns appear frequently in production systems and data-intensive applications.
Infinite Sequences
Traditional collections cannot represent infinite data—you’d exhaust memory before completing the task. Generators solve this by producing values on demand with no upper bound required.
def fibonacci():
a, b = 0, 1
while True:
yield a
a, b = b, a + b
# Grab only what you need
fib = fibonacci()
for _ in range(10):
print(next(fib)) # 0, 1, 1, 2, 3, 5, 8, 13, 21, 34
This pattern is invaluable for generating unique IDs, simulating streams of sensor data, or implementing mathematical sequences. The generator maintains its internal state between calls, producing the next value only when explicitly requested. No list grows unbounded in memory—the generator occupies constant space regardless of how many values it ultimately yields.
Data Pipelines
Generators chain together naturally to form processing pipelines, where each stage transforms or filters data lazily. This mirrors Unix pipe semantics and keeps each transformation modular and testable.
def read_lines(file_path):
with open(file_path) as f:
for line in f:
yield line.strip()
def filter_non_empty(lines):
for line in lines:
if line:
yield line
def to_uppercase(lines):
for line in lines:
yield line.upper()
# Compose the pipeline
pipeline = to_uppercase(filter_non_empty(read_lines("data.txt")))
for processed_line in pipeline:
print(processed_line)
Each generator in the pipeline processes one element at a time. Data flows through the entire chain without materializing intermediate lists. This approach scales to arbitrarily large files because only a single line resides in memory at any given moment.
Large Dataset Processing
When working with CSV files containing millions of rows, loading everything into a list is impractical. Generators offer a clean solution:
import csv
def process_large_csv(file_path):
with open(file_path, newline='') as f:
reader = csv.reader(f)
next(reader) # Skip header
for row in reader:
yield {"name": row[0], "value": float(row[1])}
# Process rows one at a time
for record in process_large_csv("large_dataset.csv"):
if record["value"] > 100:
print(record["name"])
Contrast this with loading the entire file via [row for row in csv.reader(open("large_dataset.csv"))], which consumes gigabytes of RAM for large files.
Key takeaway: Generators let you decouple what you produce from when you produce it. Whether you’re modeling infinite mathematical sequences, building composable data pipelines, or streaming through datasets that exceed available memory, generators provide a clean abstraction that scales with your problem rather than against your hardware.
Advanced Generator Patterns: send(), Chaining, and Coroutines
Beyond basic iteration, generators support powerful patterns that transform them from simple iterators into sophisticated tools for bidirectional data processing and cooperative multitasking.
The send() Method
While yield produces values out of a generator, send() pushes values into one. This bidirectional communication turns generators into coroutines—functions that can both produce and consume data.
def running_average():
total = 0.0
count = 0
average = None
while True:
value = yield average
total += value
count += 1
average = total / count
# Usage
avg = running_average()
next(avg) # Prime the generator (advances to first yield)
print(avg.send(10)) # 10.0
print(avg.send(20)) # 15.0
print(avg.send(30)) # 20.0
The first call to next() is essential—it advances execution to the yield expression where the generator pauses and waits for input. Each subsequent send() call resumes execution, assigns the sent value to value, and runs until the next yield.
Generator Chaining with yield from
Python 3.3 introduced yield from to simplify delegation to sub-generators:
def chain(*iterables):
for it in iterables:
yield from it
combined = chain(range(3), range(10, 13))
print(list(combined)) # [0, 1, 2, 10, 11, 12]
yield from delegates iteration to a sub-generator, forwarding send() and throw() calls transparently. Without it, you’d need an explicit loop with individual yield statements for each sub-iterator. This makes yield from indispensable for composing complex generator hierarchies.
Coroutine Foundations
Before async/await existed, developers built cooperative concurrency on generator coroutines. The pattern relies on three methods to manage execution flow:
send(value)— resumes the generator and injects a value at theyieldpointthrow(exception)— raises an exception inside the generator at the suspension pointclose()— raisesGeneratorExit, signaling the generator to clean up
While async/await has largely replaced raw generator coroutines for I/O-bound concurrency, understanding this foundation clarifies how Python’s async machinery works internally—asyncio was originally built on precisely these primitives.
These advanced patterns demonstrate that generators are far more than memory-efficient iterators. They provide a lightweight mechanism for building pipelines, managing state, and coordinating concurrent workflows without threads or callbacks.
Common Pitfalls and Best Practices for Production Code
Working with generators in production introduces subtle issues that can lead to hard-to-debug problems. Understanding these pitfalls early will save you significant troubleshooting time.
Generator Exhaustion
The most common mistake is attempting to iterate over a generator more than once. Unlike lists, generators are single-use iterables. Once exhausted, they produce no further values and raise no errors—they simply appear empty.
squares = (x ** 2 for x in range(5))
# First iteration works fine
first_pass = list(squares) # [0, 1, 4, 9, 16]
# Second iteration yields nothing
second_pass = list(squares) # [] — silently empty
This behavior becomes particularly dangerous when you pass a generator to multiple functions expecting to consume the same data. If you need multiple passes, either convert to a list first or recreate the generator.
Holding References to Large Generator Chains
When you chain generators into data pipelines, ensure you don’t inadvertently hold references to intermediate results. Storing a reference to an intermediate generator while also consuming the final output defeats the memory efficiency that motivated using generators in the first place.
Silent Failures During Debugging
Printing a generator object directly does not reveal its contents—you see something like <generator object <genexpr> at 0x7f007ac5d080>. This catches newcomers off guard during debugging. To inspect values without fully consuming the generator, use itertools.islice:
import itertools
def infinite_sequence():
num = 0
while True:
yield num
num += 1
gen = infinite_sequence()
# Peek at the first 5 values without exhausting the generator
print(list(itertools.islice(gen, 5))) # [0, 1, 2, 3, 4]
Best Practices
Follow these guidelines to use generators reliably in production:
- Document exhaustion semantics. If a function returns a generator, make this explicit in docstrings so callers know they cannot reuse it.
- Prefer generator expressions for simple transformations. Use the
(expression for item in iterable)syntax when the logic fits a single line. Reserveyield-based functions for multi-step or stateful logic. - Use
itertoolsliberally. Functions likechain,islice, andteehandle common generator manipulation patterns without forcing materialization into memory. - Wrap infinite generators with safeguards. Always pair infinite sequences with explicit termination conditions or
islicelimits to prevent runaway loops in production. - Handle exceptions inside generators carefully. An unhandled exception inside a generator closes it permanently. Use try/except blocks within the generator body and consider logging before re-raising.
By internalizing these practices, you write generator-based code that remains predictable, memory-efficient, and maintainable as your codebase scales.
Conclusion
Generators represent one of Python’s most elegant solutions to the perennial challenge of writing memory-efficient, scalable code. Throughout this post, we’ve traced a path from the iterator protocol through yield mechanics, generator expressions, practical use cases, advanced patterns, and production best practices.
The core takeaways are straightforward but powerful:
- Lazy evaluation allows you to process datasets that exceed available memory by generating one item at a time.
- Automatic state management between
yieldcalls eliminates the boilerplate of class-based iterators. - Composability enables you to chain generators into data pipelines with clean, modular transformation stages.
- Generator expressions offer concise syntax for simple cases, mirroring list comprehensions without the memory overhead.
We saw that generators can model finite sequences efficiently, but they also unlock patterns impossible with eager evaluation—infinite sequences that produce integers indefinitely without exhausting memory, and bidirectional coroutines that both emit and accept data.
When to Reach for Generators
Not every problem demands a generator. Use them when you need to:
- Stream large files or network responses line by line.
- Build multi-stage data processing pipelines where each stage filters or transforms records.
- Represent sequences whose length is unknown or unbounded at creation time.
- Reduce peak memory consumption in batch processing or ETL workflows.
For small, bounded collections where you need random access or repeated iteration, standard lists remain the pragmatic choice.
Moving Forward
Mastering generators positions you to write Python code that scales gracefully. As you integrate them into your projects, explore adjacent topics like itertools for generator composition, yield from for sub-generator delegation, and asynchronous generators (async def with yield) for non-blocking I/O pipelines. Each builds on the foundational mechanics covered here.
Generators embody a broader principle in software engineering: produce only what you need, when you need it. Internalize that principle, and you’ll find applications for lazy evaluation well beyond Python—across streaming architectures, reactive systems, and functional programming paradigms. Start small, profile your memory usage, and let generators prove their value in your own codebase.
Frequently Asked Questions
Q: What is the difference between a generator and a list comprehension in Python?
A: A list comprehension creates the entire list in memory at once, while a generator produces values lazily—one at a time on demand. This makes generators far more memory-efficient for large datasets, as they only hold one value in memory at any given time.
Q: How does the yield keyword work in Python generator functions?
A: The yield keyword suspends the function’s execution state and returns a value to the caller. When the next value is requested via next() or a for loop, the function resumes exactly where it left off, retaining all local variables and execution context.
Q: When should I use a generator instead of a list in Python?
A: Use generators when working with large datasets, streaming data, or infinite sequences where loading all values into memory is impractical. They are ideal when you only need to iterate through values once and don’t require random access or the len() function.
Q: What happens when a Python generator is exhausted?
A: When a generator has no more values to yield, it raises a StopIteration exception. In a for loop, this exception is caught automatically and the loop terminates gracefully. Calling next() on an exhausted generator will raise StopIteration explicitly.
Q: What is the difference between a generator function and a generator expression?
A: A generator function uses the def keyword and contains one or more yield statements, allowing complex logic. A generator expression uses parentheses syntax like (x**2 for x in range(10)) and is a concise, inline alternative for simple transformations—similar to list comprehensions but lazy.