The Two Paths to Customizing Large Language Models
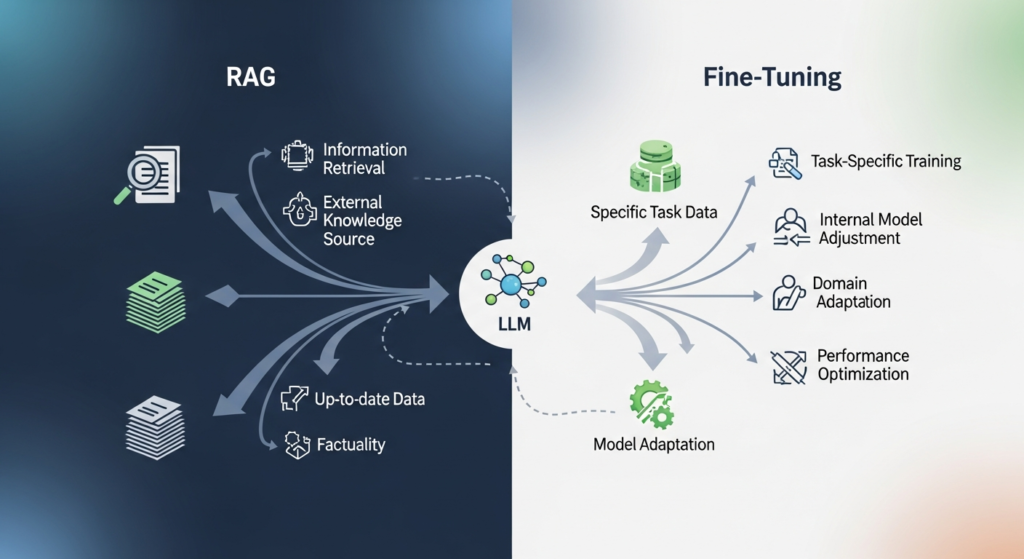
When building LLM-powered applications for domain-specific use cases, engineers inevitably face a fundamental architectural decision: how do you inject specialized knowledge into a general-purpose model? The two dominant paradigms—Retrieval-Augmented Generation (RAG) and fine-tuning—represent fundamentally different philosophies for solving this problem. One operates at inference time by dynamically retrieving external context; the other permanently alters model weights through additional training on curated datasets. Choosing between them (or combining them) has profound implications for accuracy, latency, cost, maintainability, and the long-term trajectory of your AI system.
The Core Distinction
RAG and fine-tuning diverge at the point where knowledge enters the generation pipeline.
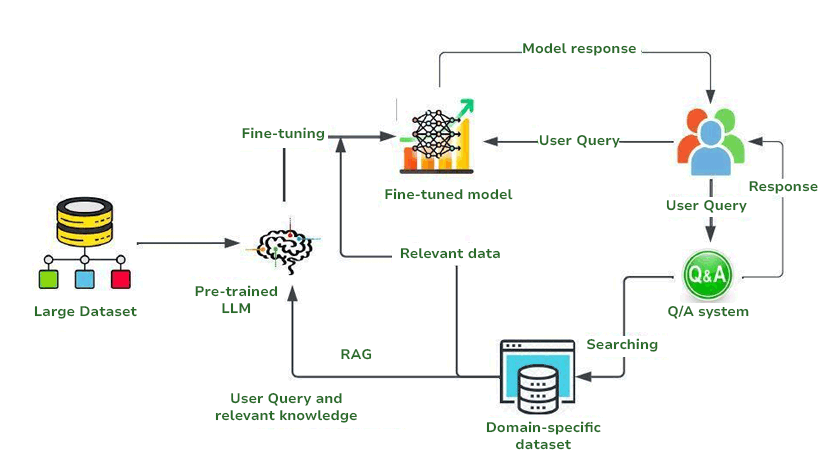
RAG connects an LLM to stores of current, private data that would otherwise be inaccessible to it. At query time, a retrieval component (typically a vector database) paired with an embedding model, fetches relevant documents and injects them into the prompt context. The model’s weights remain unchanged. With the added context of domain-specific data, RAG-augmented models produce more accurate answers than they would without it, and they do so without a single gradient update.
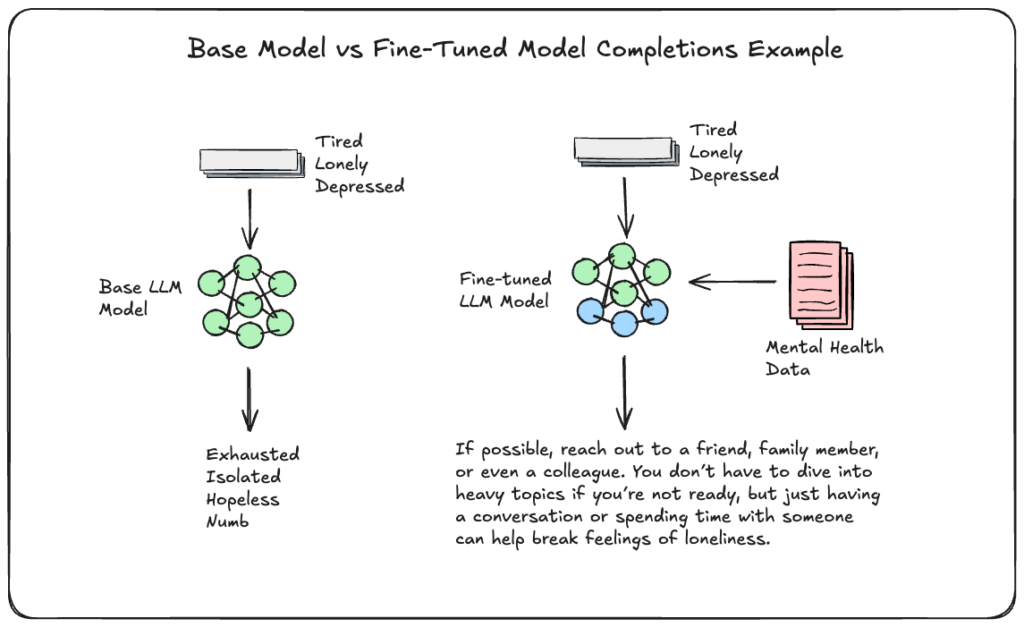
Fine-tuning, by contrast, modifies the model itself. Through techniques like Supervised Fine-Tuning (SFT), instruction tuning, or parameter-efficient methods such as LoRA, you train the model on labeled, domain-specific examples. This permanently changes model behavior—encoding new knowledge, stylistic patterns, or task-specific reasoning directly into the weights. A fine-tuned model typically outperforms its corresponding base model on the domain it was trained for.
The difference is structural, not superficial. RAG is modular and adaptable—you can swap out the knowledge base without retraining. Fine-tuning is intrinsic and persistent—the model carries its specialized knowledge wherever it’s deployed, even offline.
Why This Decision Matters Now
The proliferation of foundation models (GPT-5, Gemini, Claude) has shifted the engineering challenge from building models to customizing them. Most production systems don’t need a new architecture but a reliable way to ground a powerful general model in specific, often proprietary, data. Consider these practical scenarios:
- A legal tech platform needs to reference the latest case law and regulatory filings—data that changes weekly. RAG’s dynamic retrieval makes it a natural fit.
- A medical coding assistant must consistently output structured ICD-10 codes in a precise format. Fine-tuning encodes that formatting discipline into the model’s behavior.
- An enterprise knowledge bot needs to cite internal documentation with transparent sourcing. RAG provides traceable retrieval paths.
The Real Engineering Trade-off
This choice shapes how your AI application will perform, scale, and adapt over time. RAG excels when you need current information, have limited training resources, or require transparent sourcing. Fine-tuning shines for specialized tasks requiring consistent formatting, domain expertise, or offline deployment. But the decision isn’t always binary. There are hybrid architectures that combine a fine-tuned base model with RAG retrieval are increasingly common in production systems.
The sections that follow dissect each approach across the dimensions that matter most in production: data requirements, computational cost, latency profiles, accuracy characteristics, and maintenance burden. The goal isn’t to declare a winner but to give you a rigorous framework for making this decision in the context of your specific constraints. In practice, the right answer depends less on which technique is theoretically superior and more on the shape of your data, the nature of your task, and the operational realities of your deployment environment.
How RAG Works: Augmenting LLMs with External Knowledge at Query Time
Retrieval-Augmented Generation addresses one of the most fundamental limitations of large language models: their knowledge is frozen at training time. Rather than modifying the model’s internal parameters, RAG dynamically injects relevant external knowledge into the prompt at inference time, enabling the LLM to generate responses grounded in up-to-date, domain-specific data it never encountered during pretraining.
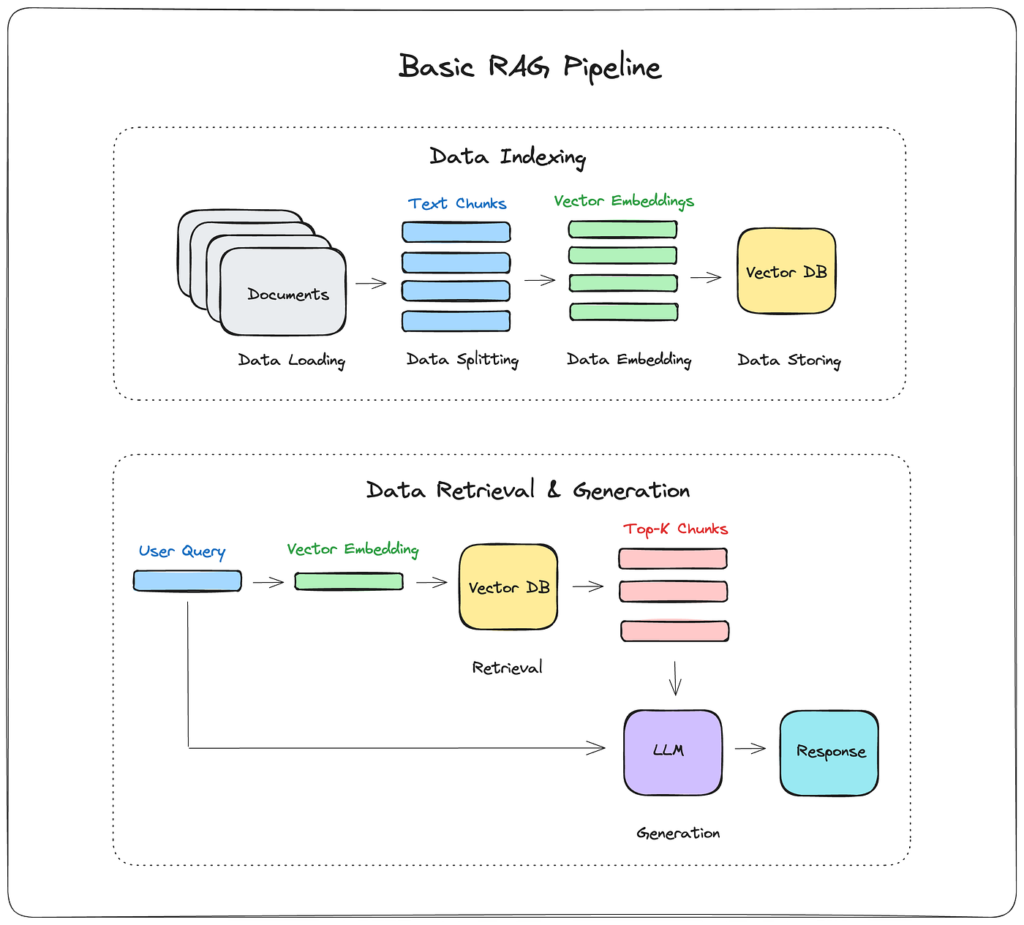
The RAG Pipeline: Core Architecture
A RAG system operates through three distinct phases: indexing, retrieval, and generation.
During indexing, your external knowledge base—documents, databases, APIs, wikis—is chunked into manageable segments, embedded into dense vector representations, and stored in a vector database (e.g., Pinecone, Weaviate, Chroma, or FAISS). This preprocessing step transforms unstructured text into a searchable semantic space.
At query time, the user’s input is embedded using the same embedding model, and a similarity search retrieves the top-k most relevant chunks from the vector store. These retrieved passages are then concatenated with the original query into an augmented prompt, which the LLM processes to generate its final response.
A code snippet showing basic RAG pipeline using Langchain:
# --- Setup ---
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.llms import OpenAI
# Step 1: Embed documents
docs = ["RAG improves factual grounding", "Fine-tuning updates model weights"]
embeddings = OpenAIEmbeddings()
vector_store = FAISS.from_texts(docs, embeddings)
# Step 2: Retrieve relevant context
query = "What is RAG?"
retrieved_docs = vector_store.similarity_search(query, k=2)
context = "\n".join([doc.page_content for doc in retrieved_docs])
# Step 3: Prompt augmentation
prompt = f"""
Answer the question using the context below:
Context:
{context}
Question: {query}
"""
# Step 4: Generate response
llm = OpenAI()
response = llm(prompt)
print(response)This architecture means the LLM never needs retraining to access new information. By connecting the model to external data stores, RAG enables it to return more accurate, contextually grounded answers than it could produce from parametric memory alone.
Why RAG Excels for Knowledge-Intensive Applications
RAG offers several architectural advantages that make it particularly attractive for production systems:
- No model modification required. You work with the base LLM as-is, reducing computational overhead and eliminating the risk of catastrophic forgetting—a common fine-tuning pitfall where the model loses general capabilities.
- Real-time knowledge updates. Swapping or updating documents in the vector store immediately changes the model’s accessible knowledge, with zero retraining cost.
- Source attribution. Because retrieved passages are explicit, you can surface citations alongside generated answers. This is critical for compliance-sensitive domains like healthcare, legal, and finance.
- Cost efficiency. RAG avoids the GPU-intensive training loops that fine-tuning demands. For many teams, the infrastructure cost of a vector database and an embedding model is significantly lower than running fine-tuning jobs on large models.
Where RAG Hits Its Limits
RAG is not without trade-offs. Retrieval quality directly bounds generation quality—if the retriever surfaces irrelevant or noisy chunks, the LLM will hallucinate or produce incoherent output. Chunk size, overlap strategy, embedding model selection, and re-ranking all become critical parameters that require careful optimization.
RAG also introduces latency overhead. Every query triggers an embedding computation and a vector search before generation begins. For latency-sensitive applications, this added round-trip can be significant, especially at scale.
There’s also a context window constraint. Even with models supporting 128k+ token windows, stuffing too many retrieved passages into the prompt can dilute the signal, increase cost per query, and degrade response quality. This phenomenon is sometimes called “lost in the middle.”
When to Reach for RAG First
RAG is your strongest option when the task demands access to frequently changing data, proprietary knowledge bases, or auditable answers. It’s the natural starting point for enterprise Q&A systems, customer support bots over internal documentation, and any application where the knowledge base evolves faster than a retraining cycle allows.
Many production use cases ultimately benefit from combining RAG with fine-tuning. But if you’re choosing where to invest first, RAG delivers immediate, measurable accuracy gains with minimal infrastructure commitment—making it the pragmatic default for teams building their first LLM-powered application against domain-specific data.
With a clear understanding of how RAG operates, let’s examine the alternative: embedding domain expertise directly into the model’s weights through fine-tuning.
How Fine-Tuning Works: Embedding Domain Expertise into Model Weights
Fine-tuning takes the opposite approach to RAG. Instead of retrieving external knowledge at inference time, it fundamentally alters a pre-trained language model by updating its internal parameters through additional training on a domain-specific dataset. The result is a self-contained system that bakes knowledge directly into the model’s weights, eliminating the need for external data stores to generate specialized responses.
The Mechanics of Parameter Updates
At its core, fine-tuning applies supervised learning to an already pre-trained foundation model. You provide curated input-output pairs that represent the desired behavior, and the training loop adjusts the model’s weights via backpropagation. The base model, whether GPT-5, LLaMA, or Mistral, retains its general language understanding while shifting its probability distributions to favor domain-specific patterns, terminology, and reasoning structures.
A code snippet showing the fine-tuning pipeline:
# --- Setup ---
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, Trainer
from peft import LoraConfig, get_peft_model
from datasets import Dataset
# Step 1: Prepare dataset
data = {
"text": [
"### Question: What is RAG?\n### Answer: Retrieval-Augmented Generation...",
"### Question: What is fine-tuning?\n### Answer: Updating model weights..."
]
}
dataset = Dataset.from_dict(data)
# Step 2: Load model + tokenizer
model_name = "gpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Step 3: Apply LoRA
lora_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules=["c_attn"],
lora_dropout=0.1
)
model = get_peft_model(model, lora_config)
# Step 4: Tokenization
def tokenize(example):
return tokenizer(example["text"], truncation=True, padding="max_length")
tokenized_dataset = dataset.map(tokenize)
# Step 5: Training loop
training_args = TrainingArguments(
output_dir="./ft-model",
per_device_train_batch_size=2,
num_train_epochs=3,
logging_steps=10
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset
)
trainer.train()Modern approaches like LoRA (Low-Rank Adaptation) and QLoRA have dramatically reduced the computational overhead. Instead of updating all parameters, which can number in the billions, these techniques freeze the base weights and inject small, trainable rank-decomposition matrices into transformer layers. This makes it possible to fine-tune a 70B-parameter model on a single high-end GPU, putting the technique within reach of far more teams than full-parameter training ever allowed.
When Domain Expertise Must Be Intrinsic
Fine-tuning shines in scenarios where the model needs to internalize specialized knowledge rather than look it up:
- Medical diagnosis support: A model fine-tuned on clinical notes and diagnostic criteria develops an intrinsic understanding of medical terminology, symptom-disease correlations, and clinical reasoning patterns.
- Legal document generation: Fine-tuned models produce contracts and briefs that consistently follow jurisdictional formatting conventions and legal phrasing without retrieval augmentation.
- Code generation for proprietary frameworks: When your internal SDK has conventions that don’t exist in public training data, fine-tuning teaches the model to generate idiomatic code natively.
A fine-tuned LLM typically outperforms its corresponding base model on domain-specific tasks because it develops a deeper understanding of specialized terminologies and contexts. The model doesn’t just access domain knowledge—it reasons with it.
The Trade-offs You Must Account For
Fine-tuning comes with meaningful costs. The process demands high-quality, curated training data—often hundreds to thousands of labeled examples at minimum. Data preparation alone can consume significant engineering time.
There’s also the risk of catastrophic forgetting, where aggressive fine-tuning on narrow data degrades the model’s general capabilities. Techniques like learning rate scheduling, mixed-task training, and parameter-efficient methods mitigate this risk, but they require careful calibration.
Additionally, fine-tuned models produce static knowledge snapshots. Unlike RAG systems that can point to updated documents in real time, a fine-tuned model’s knowledge is frozen at training time. If your domain data changes frequently like stock prices, regulatory updates, product catalogs, fine-tuning alone won’t keep the model current without periodic retraining.
Deployment Considerations
One compelling advantage of fine-tuning is deployment simplicity. A fine-tuned model is self-contained: no vector databases, no retrieval pipelines, no embedding indices. This makes it particularly effective for offline or edge deployment scenarios where network access is limited. It also reduces inference latency since there’s no retrieval step preceding generation.
For teams building latency-sensitive applications or operating in air-gapped environments, this architectural simplicity can be decisive. The model carries its expertise in its weights, ready to generate responses without external dependencies.
Now that we’ve examined both approaches individually, let’s put them side by side to see how they compare across the dimensions that matter most in production.
RAG vs Fine-Tuning: A Head-to-Head Comparison Across Key Dimensions
Choosing between RAG and fine-tuning requires evaluating multiple technical and operational factors that directly impact your application’s performance, maintainability, and cost profile. Here’s how the two approaches stack up across the dimensions that matter most to practitioners building production systems.
Knowledge Currency and Data Freshness
RAG maintains a decisive advantage when your application depends on up-to-date information. Because it retrieves context from external data stores at inference time, updating knowledge is as simple as refreshing your vector database or document index—no retraining required. Fine-tuning bakes knowledge into model weights at training time, so every shift in your domain data triggers a retraining cycle. For applications like internal knowledge bases, customer support systems, or compliance tools where information changes weekly or monthly, RAG provides a fundamentally more sustainable architecture.
Task Specialization and Output Control
Fine-tuning excels when you need the model to internalize consistent formatting, tone, or domain-specific reasoning patterns. A fine-tuned model outperforms its corresponding base model on specialized tasks because it has encoded domain understanding directly into its parameters. Think structured medical report generation, legal clause drafting, or code generation in a proprietary DSL. RAG can guide outputs through retrieved context, but it cannot reshape the model’s fundamental behavior or enforce strict output schemas with the same reliability.
Resource Requirements and Infrastructure Complexity
Each approach demands a different kind of engineering overhead:
- RAG requires building and maintaining a retrieval pipeline: embedding models, vector stores (e.g., Pinecone, Weaviate, pgvector), chunking strategies, and re-ranking logic. The LLM itself remains untouched.
- Fine-tuning requires curated training datasets, GPU compute for training runs, hyperparameter optimization, and ongoing evaluation to detect drift or catastrophic forgetting.
RAG tends to have lower upfront compute costs but introduces latency at inference time due to the retrieval step. Fine-tuning demands significant upfront investment but can yield a smaller, more efficient model that runs faster at inference—a critical consideration for edge deployment or latency-sensitive applications.
Transparency and Auditability
RAG provides a natural mechanism for source attribution. Every generated response can be traced back to the specific documents or passages that informed it, making it invaluable in regulated industries where transparent sourcing is non-negotiable. Fine-tuned models offer no such traceability—knowledge is distributed across millions of parameters with no clear provenance chain.
Generalization vs. Depth
Fine-tuning carries an inherent risk: catastrophic forgetting. As the model specializes, it may lose some of its general capabilities. RAG sidesteps this entirely because the base model remains unmodified. However, for niche domains requiring deep understanding of specialized terminologies or contexts where retrieved passages alone cannot compensate for a model’s lack of domain fluency, fine-tuning delivers superior results.
The Hybrid Sweet Spot
In practice, the most robust production systems combine both approaches. You fine-tune a model to understand your domain’s language and output requirements, then layer RAG on top to inject current, retrievable context at inference time. This hybrid pattern captures the strengths of each: the behavioral consistency of fine-tuning with the knowledge freshness and auditability of RAG.
The right choice or combination depends on your specific constraints: data volatility, latency budgets, compliance requirements, and available compute. There is no universal answer, but understanding these trade-offs equips you to make an informed architectural decision rather than a reactive one.
When to Choose RAG and When to Choose Fine-Tuning: Use Cases and Decision Criteria
Understanding the technical trade-offs is essential, but translating them into concrete decisions requires a practical framework. The choice between RAG and fine-tuning isn’t binary—it’s an engineering trade-off that depends on your data characteristics, latency requirements, infrastructure constraints, and the nature of the task itself.
Decision Criteria: Six Key Questions
Before committing to either approach, evaluate your use case against these critical dimensions:
How frequently does your knowledge base change? If your domain data updates daily or weekly—think financial markets, news aggregation, or product catalogs—RAG provides a clear advantage. It decouples knowledge from model weights, so you update your vector store without retraining. Fine-tuning bakes knowledge into parameters, making it stale the moment your corpus shifts.
Do you need source attribution and traceability? RAG architectures inherently support transparent sourcing. Each generated response can reference the retrieved documents, enabling audit trails critical in regulated industries like healthcare and finance. Fine-tuned models generate from learned distributions without pointing to specific sources.
Is your task about knowledge or behavior? This distinction matters enormously. If you need the model to know things (facts, policies, technical documentation), RAG retrieves that knowledge at inference time. If you need the model to behave differently—adopting a specific tone, producing structured outputs, or mastering domain-specific reasoning patterns—fine-tuning reshapes behavior at the weight level.
What are your compute and budget constraints? Fine-tuning requires GPU hours for training, curated datasets, and ongoing retraining pipelines. RAG requires vector database infrastructure and adds retrieval latency at inference. Evaluate which cost profile aligns with your operational model.
Will the model operate offline or in air-gapped environments? Fine-tuned models are self-contained. RAG depends on external retrieval infrastructure. For edge deployment or environments without reliable network access, fine-tuning is often the only viable path.
How specialized is the domain vocabulary? Models struggle with highly specialized terminology they haven’t encountered during pretraining. Fine-tuning on domain corpora—medical literature, legal statutes, semiconductor specifications—teaches the model to fluently use and reason with that vocabulary in ways RAG alone cannot achieve.
Use Case Mapping
| Use Case | Recommended Approach | Rationale |
|---|---|---|
| Customer support with live docs | RAG | Frequently updated knowledge, source citation |
| Medical report generation | Fine-tuning + RAG | Domain behavior + current patient data |
| Internal code assistant | RAG | Codebase changes constantly |
| Legal contract drafting | Fine-tuning | Consistent formatting, domain tone |
| Real-time news summarization | RAG | Data freshness is paramount |
| Embedded/edge deployment | Fine-tuning | No retrieval infrastructure available |
The Hybrid Approach: Combining Both
For most production systems, the optimal architecture combines both techniques. Fine-tune your base model to internalize domain-specific behavior, reasoning patterns, and output formatting. Then layer RAG on top to inject current, factual knowledge at inference time. This combination delivers a model that speaks the language of your domain (via fine-tuning) while staying grounded in up-to-date facts (via retrieval).
Teams that invest in fine-tuning often find that adding RAG becomes a natural extension. The reverse is also true—teams that start with RAG frequently discover behavioral gaps that only fine-tuning can close.
Practical Recommendation
Start with RAG if you need fast iteration and your primary gap is knowledge. Start with fine-tuning if your primary gap is behavior or output quality. Plan for both. The most resilient LLM applications treat these techniques as complementary layers in a single system, not competing alternatives.
The Hybrid Approach: Combining RAG and Fine-Tuning for Production Systems
As the previous sections suggest, the RAG-versus-fine-tuning decision rarely resolves to a clean binary in practice. Production systems that demand both domain expertise and access to evolving knowledge bases benefit most from a hybrid architecture—one that fine-tunes a base model for task-specific behavior while layering RAG on top to ground outputs in retrievable, up-to-date evidence. The key is understanding where each technique contributes and how to orchestrate them effectively.
Why Hybrid Outperforms Either Approach Alone
Fine-tuning adjusts model weights to internalize domain-specific patterns: terminology, output formatting, reasoning heuristics, and stylistic conventions. RAG injects external context at inference time, keeping the model anchored to verifiable sources without retraining. When combined, you get a model that knows how to reason about your domain (fine-tuning) and has access to the latest facts it needs to reason over (RAG).
Consider a clinical decision-support system. Fine-tuning on medical literature and structured clinical notes teaches the model to produce outputs in the expected diagnostic format and to handle domain jargon fluently. But medical guidelines change—new drug interactions surface, treatment protocols get revised. RAG ensures the model retrieves the most current guidelines from a curated knowledge store at query time, eliminating the need for continuous retraining cycles.
Architectural Patterns for the Hybrid Pipeline
A typical hybrid architecture follows this flow:
- Fine-tune a base LLM on domain-specific corpora to optimize for task structure, tone, and specialized reasoning.
- Build a retrieval layer (vector store + embedding model) over your dynamic knowledge base.
- Compose a prompt pipeline that merges retrieved context with the fine-tuned model’s inference capabilities.
- Implement a routing or gating mechanism that decides when retrieval is necessary versus when the fine-tuned model’s parametric knowledge suffices.
Practical Considerations for Production Deployment
Combining both approaches introduces additional complexity. Keep these trade-offs in mind:
- Cost profile: Fine-tuning incurs upfront compute costs; RAG adds per-query latency and infrastructure overhead for the retrieval layer. Budget for both.
- Evaluation strategy: You need separate evaluation harnesses—one measuring the fine-tuned model’s task accuracy in isolation, another measuring end-to-end retrieval quality (precision@k, recall, faithfulness scores).
- Data governance: RAG makes sourcing transparent, which matters for compliance. Fine-tuning bakes knowledge into weights, making it harder to audit. The hybrid approach lets you lean on RAG for traceability while relying on fine-tuning for behavioral consistency.
- Maintenance cadence: Update your retrieval index frequently (days or hours); re-fine-tune less often (weeks or months) when task requirements shift or model drift becomes measurable.
When to Start Hybrid vs. Start Simple
Not every project warrants the hybrid approach on day one. If your use case is primarily about accessing current information with transparent sourcing, start with RAG over a general-purpose model and measure performance gaps. If the model struggles with output format, domain-specific reasoning, or consistency, introduce fine-tuning incrementally. This staged approach reduces upfront investment while giving you clear empirical signals about where each technique adds value.
The hybrid strategy represents the mature end-state for most serious LLM deployments. It combines the adaptability and auditability of retrieval with the precision and behavioral control of weight optimization—delivering systems that are both knowledgeable and grounded.
Cost, Infrastructure, and Implementation Trade-Offs for Engineering Teams
Beyond model performance, the choice between RAG and fine-tuning directly impacts infrastructure costs, operational complexity, and long-term maintainability. Understanding these trade-offs at a systems level is critical before committing engineering resources.
Compute and Infrastructure Costs
Fine-tuning demands significant upfront compute. Training a domain-specific adapter on a 7B-parameter model requires GPU hours on A100s or equivalent hardware, and scaling to larger models pushes costs into thousands of dollars per training run. Each iteration—hyperparameter sweep, dataset revision, or domain expansion—multiplies that expense. You also need robust experiment tracking, versioned datasets, and model registries to manage the lifecycle.
RAG shifts the cost profile toward inference-time retrieval. The primary infrastructure investment goes into a vector database (Pinecone, Weaviate, Qdrant, or pgvector), an embedding pipeline, and a chunking/indexing strategy. While you avoid expensive training loops, you introduce latency overhead from retrieval queries and pay per-token costs for the enlarged context window at inference. For high-throughput applications, these retrieval costs compound quickly.
Implementation Complexity
RAG pipelines introduce a broader surface area of engineering concerns. Teams must build and maintain document ingestion workflows, chunking strategies, embedding models, retrieval ranking logic, and context assembly—all before the prompt ever reaches the LLM. Each component introduces potential failure modes: stale indexes, poor chunk boundaries, irrelevant retrievals that degrade output quality. Debugging a bad response means tracing through the entire retrieval chain, not just the model itself.
Fine-tuning concentrates complexity in the training phase. Once you’ve curated a high-quality dataset and completed training, the deployment artifact is a single model endpoint. This simplifies the inference architecture considerably and eliminates runtime dependencies on external data stores. However, the reverse path—bolting fine-tuning onto an existing RAG system—requires substantially more effort than adding RAG to a fine-tuned model.
Data Freshness and Update Cadence
One of RAG’s strongest operational advantages is data currency. Updating knowledge requires only re-indexing new documents—no retraining, no GPU allocation, no model validation. For applications where information changes daily (compliance databases, product catalogs, internal knowledge bases), this is a decisive factor. Fine-tuned models encode knowledge at training time; refreshing that knowledge means retraining, which introduces both cost and delay into the update cycle.
Team Skill Requirements
Consider your team’s existing capabilities:
- RAG demands strong data engineering skills—building reliable ETL pipelines, optimizing retrieval relevance, and managing vector infrastructure.
- Fine-tuning requires ML engineering depth—dataset curation, training orchestration, evaluation frameworks, and familiarity with techniques like LoRA or QLoRA.
- Hybrid approaches require both skill sets, plus the architectural judgment to determine which knowledge belongs in the model’s weights versus the retrieval layer.
The Pragmatic Path Forward
For most production teams, the decision isn’t binary. Start with RAG when you need rapid iteration, transparent sourcing, and access to frequently updated data. Invest in fine-tuning when you need consistent output formatting, specialized domain reasoning, or reduced inference latency. Optimize for the constraints that matter most to your deployment context, not for theoretical benchmarks.
Making the Right Architectural Choice for Your AI Application
The decision between RAG and fine-tuning isn’t binary—it’s architectural. Like choosing between microservices and a monolithic deployment, the right answer depends on your system’s constraints, your data lifecycle, and the specific behavior you need from your model in production.
Evaluate Your Data Dynamics First
Start with a fundamental question: how frequently does your knowledge base change? If your application must reflect real-time or frequently updated information—regulatory documents, product catalogs, internal knowledge bases—RAG provides a clear advantage. It decouples the knowledge layer from the model weights, allowing you to update retrieval indices without retraining. Fine-tuning bakes knowledge into model parameters at training time—powerful for stable domains, but a liability when facts shift.
Use this decision matrix as a starting point:
| Criterion | Favor RAG | Favor Fine-Tuning |
|---|---|---|
| Data update frequency | High / continuous | Low / stable |
| Need for source attribution | Critical | Not required |
| Output format consistency | Flexible | Strict / specialized |
| Compute budget (ongoing) | Inference overhead | Training overhead |
| Deployment environment | Cloud / connected | Edge / offline |
| Domain specialization depth | Moderate | Deep |
When to Combine Both Approaches
For most production systems of meaningful complexity, the answer isn’t either-or—it’s a hybrid architecture. Once teams invest in fine-tuning a model for domain-specific behavior, adding RAG becomes a natural extension that compounds performance gains. A fine-tuned model produces more coherent, stylistically consistent outputs for your domain, while RAG grounds those outputs in current, verifiable data.
For example, a legal AI assistant might use a fine-tuned model to internalize legal reasoning patterns, citation formats, and jurisdictional nuances. Layering RAG on top then enables the system to retrieve the latest case law and statutory amendments at inference time—something the fine-tuned weights alone cannot guarantee.
Six Questions to Guide Your Decision
Before committing to an architecture, run through these evaluation criteria:
- Do you need traceable, source-attributed answers? RAG provides built-in provenance. Fine-tuning does not.
- Is your task about how the model responds or what it knows? Fine-tuning modifies behavior and style; RAG augments knowledge.
- What are your compute and infrastructure constraints? Fine-tuning demands GPU hours upfront. RAG requires vector database and retrieval infrastructure at inference time.
- Can you tolerate latency from retrieval steps? RAG adds overhead per query. Fine-tuned models generate directly from learned weights.
- How sensitive is your domain to hallucination? RAG reduces hallucination risk by anchoring responses to retrieved documents. Fine-tuned models can still confabulate confidently.
- Will you deploy in connected or disconnected environments? Fine-tuned models operate independently. RAG requires access to an external data store.
The Bottom Line
This choice shapes more than model accuracy—it defines how your AI application will scale, adapt, and maintain reliability over its lifecycle. RAG excels at keeping models grounded in current, attributable information with minimal retraining overhead. Fine-tuning excels at embedding deep domain expertise and enforcing consistent output behavior. The most robust production systems leverage both: fine-tuning to establish a strong domain-aware foundation, and RAG to keep that foundation connected to living data.
Treat this not as a one-time decision but as an evolving architectural strategy. Profile your application’s requirements rigorously, prototype both approaches against your evaluation benchmarks, and iterate. The teams that build the most effective LLM-powered systems are the ones that understand these techniques not as competing options, but as complementary tools in a unified inference stack.
Frequently Asked Questions
Q: What is the main difference between RAG and fine-tuning?
A: RAG dynamically retrieves external knowledge at inference time and injects it into the prompt, while fine-tuning permanently modifies a model’s weights through additional training on domain-specific data. RAG keeps knowledge external and updatable; fine-tuning embeds knowledge directly into the model’s parameters.
Q: When should I use RAG instead of fine-tuning for my LLM application?
A: RAG is ideal when your knowledge base changes frequently, you need source attribution and traceability, or you want to avoid the cost and complexity of retraining. It excels in use cases like enterprise search, customer support, and any scenario requiring access to up-to-date or proprietary documents.
Q: Can you combine RAG and fine-tuning together?
A: Yes. You can fine-tune a model to improve its reasoning style, tone, or format adherence, while using RAG to supply it with current, domain-specific context at inference time. This hybrid approach often delivers the best results for complex, production-grade AI systems.
Q: What are the cost implications of RAG vs fine-tuning?
A: Fine-tuning involves upfront compute costs for training and repeated costs each time the model needs updating. RAG shifts costs to infrastructure like vector databases and retrieval pipelines but avoids retraining expenses. For rapidly evolving knowledge bases, RAG is generally more cost-effective over time.
Q: Do I need a vector database to implement RAG?
A: A vector database is a core component of most RAG architectures. It stores document embeddings and enables fast semantic similarity search so the system can retrieve the most relevant context for each query. Popular options include Pinecone, Weaviate, Milvus, and pgvector for PostgreSQL.