Why Tokenization Is the Critical First Step in Every LLM Pipeline
Every large language model, whether it’s GPT, LLaMA, or a custom transformer you’re training in-house, begins its work not with words, not with sentences, but with tokens. Before a single attention head fires, before any embedding lookup occurs, raw text must be converted into a sequence of integer IDs that the model can process. This conversion step, tokenization, is not merely a preprocessing detail. It is an architectural decision that shapes vocabulary size, model efficiency, sequence length constraints, and ultimately, the quality of learned representations.
The Problem Space: From Characters to Subwords
At first glance, tokenization seems straightforward: split text into units and map each unit to an integer. But the choice of what constitutes a unit has profound implications. Consider the two naive extremes:
- Character-level tokenization assigns an integer to every individual character. The vocabulary is tiny (a few hundred entries at most), but sequences become extremely long. A sentence of 50 words might expand to 250+ tokens, straining the quadratic attention complexity of transformers and diluting semantic signal across too many positions.
- Word-level tokenization uses regex or whitespace splitting to isolate whole words, assigning each a unique ID. This keeps sequences short but explodes the vocabulary into hundreds of thousands of entries—and still fails catastrophically on unseen or rare words. Any out-of-vocabulary term at inference time becomes meaningless to the model, a hard failure with no graceful fallback.
Neither extreme scales. Character-level encoding wastes compute on redundant positional processing; word-level encoding wastes parameters on a bloated embedding matrix and cannot generalize to novel inputs. This is the fundamental tension that subword tokenization resolves—and it’s why Byte Pair Encoding (BPE) has become the dominant algorithm powering modern LLMs.
Why BPE Became the Standard
BPE operates on a simple but powerful principle: start with the smallest meaningful units (individual bytes or characters), then iteratively merge the most frequently co-occurring pairs into new tokens. The result is a vocabulary that captures common words as single tokens while decomposing rare or novel words into recognizable subword components. The word “tokenization” might be a single token in a well-trained BPE vocabulary, while an unusual term like “defenestration” gets split into subword pieces the model has still seen during training.
This approach directly addresses the shortcomings of both character-level and word-level methods:
- Bounded vocabulary size — You control the vocabulary (typically 32K–100K tokens), keeping the embedding matrix tractable.
- Open-vocabulary coverage — Any input can be encoded, because the algorithm falls back to byte-level or character-level representations for truly unknown sequences.
- Efficient sequence lengths — Common words and frequent substrings compress into single tokens, keeping sequences shorter than character-level encoding would produce.
The core idea—converting text into an integer representation (token IDs) for LLM training—sounds deceptively simple. But the implementation details matter enormously. How you handle Unicode, whitespace, special tokens, and merge priorities all affect downstream model behavior in ways that are easy to overlook and difficult to debug after the fact.

The Stakes Are Higher Than You Think
Tokenization errors don’t throw exceptions—they silently degrade performance. A poorly chosen vocabulary forces the model to spend capacity learning subword compositions that a better tokenizer would handle directly. It inflates sequence lengths, wasting context window budget. It creates artifacts in generation, producing unexpected token boundaries that surface as spelling errors or broken morphology.
For ML engineers building or fine-tuning LLMs, understanding BPE at the mechanical level isn’t optional. It’s the difference between a model that efficiently leverages its context window and one that burns tokens on redundant subword fragmentation. Every architectural decision downstream—positional encoding, context length, inference cost—traces back to how you tokenize.
What follows is a deep dive into exactly how BPE works, from its byte-level foundations to its iterative merge procedure, so you can reason precisely about the tokenizer sitting at the front of your model’s pipeline.
The Problem with Word-Level and Character-Level Tokenization: Why Neither Extreme Works
Before understanding why Byte Pair Encoding (BPE) became the dominant tokenization strategy in modern LLMs, it’s worth examining the two naive approaches it replaced—and why each one fails in practice.
Word-Level Tokenization: The Vocabulary Explosion
The most intuitive approach to tokenization is splitting text on whitespace and punctuation, then assigning a unique integer ID to each distinct word. This is conceptually simple and preserves semantic units cleanly. But it breaks down fast.
The core problem is open vocabulary. Natural language is generative—users coin new terms, make typos, use domain-specific jargon, and write in multiple languages. A word-level tokenizer trained on a fixed corpus will inevitably encounter tokens at inference time that don’t exist in its vocabulary. These out-of-vocabulary (OOV) tokens are typically mapped to a generic <UNK> token, which destroys information.
The vocabulary size itself becomes a bottleneck. English alone has hundreds of thousands of word forms when you account for inflections, compounds, and proper nouns. Scale this to multilingual models, and you’re looking at millions of unique tokens. Each token requires its own embedding vector—a row in the embedding matrix—so vocabulary size directly impacts model parameters, memory footprint, and training cost. A vocabulary of 1 million words with a 768-dimensional embedding space means ~3 GB of parameters just for the embedding layer.
There’s also a severe data sparsity issue. Rare words appear infrequently in training data, so the model never learns robust representations for them. Words like “defenestration” or “tokenizer” might appear only a handful of times, yielding undertrained embeddings that add noise rather than signal.
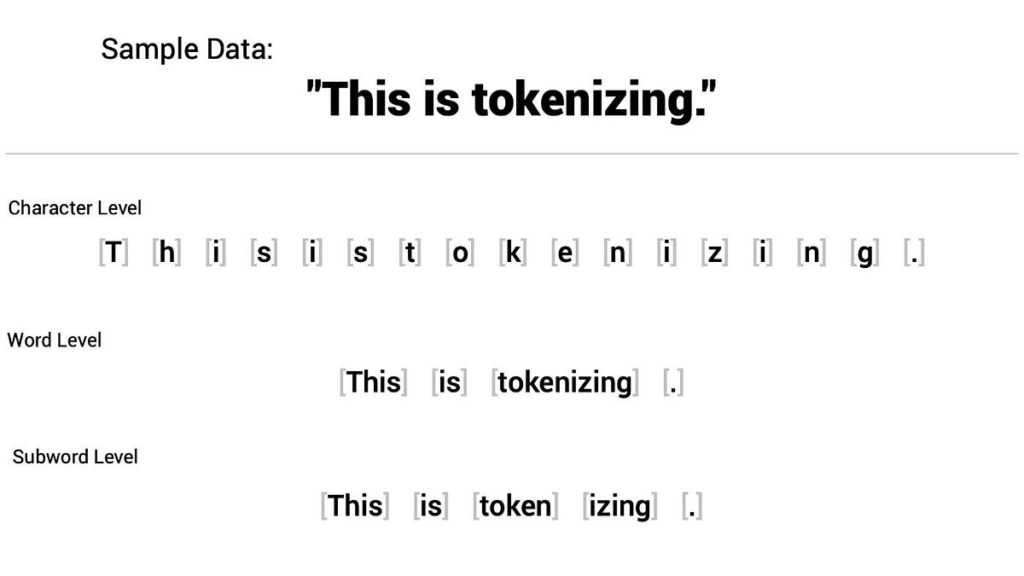
Character-Level Tokenization: The Sequence Length Problem
The opposite extreme—tokenizing at the character level—elegantly solves the OOV problem. With a vocabulary of roughly 256 bytes (or ~150 Unicode characters for English), every possible input can be represented. No <UNK> tokens, no vocabulary explosion.
But this approach introduces its own critical failure mode: sequence length. A single word like “tokenization” becomes 12 individual tokens. A typical document that might be 500 word-level tokens balloons to 2,500–3,000 character-level tokens. Since Transformer self-attention scales quadratically with sequence length—O(n²)—this dramatically increases computational cost. It also means the model’s fixed context window covers far less actual text.
More fundamentally, character-level tokenization forces the model to learn spelling from scratch. The model must discover that t-o-k-e-n forms a meaningful unit, burning capacity on orthographic patterns rather than semantic ones. This makes training slower and less sample-efficient. The model needs to build hierarchical representations from extremely low-level primitives, a task that requires significantly more data and compute to converge.
The Need for a Middle Ground
Neither extreme works because they sit at opposite ends of a granularity-efficiency tradeoff. Word-level tokenization is too coarse—brittle to novel inputs and expensive in vocabulary size. Character-level tokenization is too fine—computationally wasteful and semantically impoverished at the token level.
What practitioners need is a tokenization scheme that:
- Handles unseen inputs gracefully by decomposing rare words into known subunits
- Keeps vocabulary size manageable (typically 32K–100K tokens for modern LLMs)
- Preserves meaningful units where possible, keeping common words as single tokens
- Produces reasonable sequence lengths that don’t overwhelm the attention mechanism
This is precisely the gap that BPE fills. By operating at the subword level, BPE dynamically balances between these extremes—representing frequent words as single tokens while decomposing rare or novel words into smaller, reusable pieces. It’s this adaptive granularity that made BPE, as popularized by Sennrich et al. and later adapted to byte-level merges in the GPT-2 paper, a fundamental building block in virtually every major LLM architecture today.
Byte Pair Encoding Explained: Origins, Core Algorithm, and Step-by-Step Mechanics
Byte Pair Encoding (BPE) didn’t originate in NLP. Philip Gage introduced it in 1994 as a data compression algorithm — a simple, greedy method for replacing the most frequent pair of consecutive bytes in a data stream with a single unused byte. Decades later, Sennrich et al. (2016) repurposed this elegant idea for subword segmentation in neural machine translation, and it quickly became the dominant tokenization strategy across the field. OpenAI further adapted BPE to operate at the byte level in the GPT-2 paper (Language Models are Unsupervised Multitask Learners), cementing it as a fundamental building block in modern LLM architectures.
Why Subword Tokenization?
The core problem BPE solves is vocabulary construction. Word-level tokenization produces massive vocabularies and cannot handle out-of-vocabulary (OOV) terms. Character-level tokenization eliminates OOV issues but generates excessively long sequences, increasing computational cost and making it harder for models to learn semantic relationships. BPE strikes a balance: it decomposes rare words into meaningful subword units while keeping frequent words intact. This allows LLMs to maintain a fixed, manageable vocabulary — typically 30,000 to 100,000 tokens — while still representing any arbitrary input text.
The Core Algorithm
BPE operates in two distinct phases: training (building the vocabulary) and encoding (tokenizing new text). The training phase works as follows:
- Initialize the vocabulary with all individual bytes (or characters), giving you a base vocabulary of 256 entries when operating at the byte level.
- Scan the training corpus and count the frequency of every adjacent pair of tokens.
- Merge the most frequent pair into a single new token and add it to the vocabulary.
- Replace all occurrences of that pair in the corpus with the new merged token.
- Repeat steps 2–4 until the desired vocabulary size is reached.
Each iteration reduces the total number of tokens in the corpus by the count of the merged pair, progressively building longer subword units from shorter ones. The merge operations are recorded in order — this ordered list of merge rules is what you ship alongside the vocabulary for inference.
Step-by-Step Example
Consider training BPE on a small corpus. Start by representing text as a sequence of bytes:
# Converting text to a byte-level representation
text = "This is some text"
byte_sequence = list(text.encode("utf-8"))
print(byte_sequence)
# Output:
# [84, 104, 105, 115, 32, 105, 115, 32, 115, 111, 109, 101, 32, 116, 101, 120, 116]After initialization, suppose the most frequent adjacent pair across the corpus is (101, 120) — corresponding to the characters e and x. BPE merges this pair into a new token ID (e.g., 256), replaces every occurrence, and moves on. The next iteration might merge (256, 116) — combining the newly created ex token with t to form ext. Over thousands of iterations on a large corpus, common words like the or ing emerge as single tokens, while rare words decompose into recognizable subword pieces.
Byte-Level BPE: The Modern Standard
The byte-level variant, popularized by GPT-2 and now standard in models like GPT-5 and LLaMA, starts from raw UTF-8 bytes rather than Unicode characters. This guarantees complete coverage of any input — every possible string can be encoded without any unknown token fallback. The base vocabulary is exactly 256 byte values, and all higher-level tokens are built through learned merges. This design is particularly powerful for multilingual and code-heavy applications, where the input distribution spans diverse scripts and symbol sets.
Understanding BPE at this mechanical level is not merely academic. When you fine-tune an LLM, debug tokenization artifacts, or design a domain-specific vocabulary, the merge order, vocabulary size, and byte-level representation directly affect model performance, sequence length, and inference cost. Mastering these mechanics gives you precise control over one of the most consequential preprocessing decisions in the LLM pipeline.
From Bytes to Vocabulary: How BPE Builds Subword Tokens from Raw Text in Practice
At its core, Byte Pair Encoding (BPE) operates on a deceptively simple principle: start with the smallest possible units of text and iteratively merge the most frequent adjacent pairs until you reach a desired vocabulary size. But the practical mechanics—from raw bytes to a finalized vocabulary—involve several deliberate steps that every ML engineer working with LLMs should understand intimately.
Starting Point: Characters or Bytes?
The original BPE algorithm, adapted for NLP by Sennrich et al., operated at the character level. However, the GPT-2 paper (Language Models are Unsupervised Multitask Learners) introduced a critical evolution: byte-level BPE. Instead of initializing the vocabulary with Unicode characters—which can number in the hundreds of thousands—byte-level BPE starts with a base vocabulary of just 256 byte tokens (0x00 through 0xFF). This guarantees that any text, regardless of language or special characters, can be represented without ever encountering an out-of-vocabulary token. It’s a universality guarantee that character-level and word-level tokenizers simply cannot offer.
# Python code to demonstrate encoding a raw string into its UTF-8 byte sequence
# 1. Define a string (including a non-ASCII character to show UTF-8 in action)
raw_string = "Hello! ☕"
# 2. Encode the string into UTF-8
# The 'encode' method returns a 'bytes' object
utf8_bytes = raw_string.encode('utf-8')
# 3. Display the results
print(f"Original String: {raw_string}")
print(f"Type: {type(raw_string)}")
print("-" * 30)
print(f"UTF-8 Bytes: {utf8_bytes}")
print(f"Type: {type(utf8_bytes)}")
print(f"Hex sequence: {utf8_bytes.hex(' ')}")
print(f"Byte count: {len(utf8_bytes)} bytes")
# Output:
"""
Original String: Hello! ☕
Type: <class 'str'>
------------------------------
UTF-8 Bytes: b'Hello! \xe2\x98\x95'
Type: <class 'bytes'>
Hex sequence: 48 65 6c 6c 6f 21 20 e2 98 95
Byte count: 10 bytes
"""The Iterative Merge Process
Once the training corpus is decomposed into byte sequences, BPE begins its greedy, bottom-up construction:
- Count all adjacent byte pairs across the entire corpus.
- Identify the most frequent pair (e.g., bytes representing
tandhappearing consecutively). - Merge that pair into a single new token and add it to the vocabulary.
- Replace all occurrences of that pair in the corpus with the new merged token.
- Repeat until the vocabulary reaches a predefined size (e.g., 50,257 for GPT-2 or 100,256 for GPT-4’s
cl100k_base).
Each merge operation reduces the total number of tokens in the corpus while increasing the vocabulary by exactly one entry. Early merges typically capture common character bigrams (th, in, er), while later merges produce full subwords or even complete words (the, tion, function). The resulting merge table—an ordered list of pair merges—becomes the tokenizer’s core artifact, deterministically defining how any new input text gets segmented.
# BPE Training Implementation
from collections import Counter
def get_stats(ids, counts):
"""Finds the frequency of all adjacent pairs of tokens."""
pair_counts = Counter()
for word_ids, freq in counts.items():
for i in range(len(word_ids) - 1):
pair = (word_ids[i], word_ids[i+1])
pair_counts[pair] += freq
return pair_counts
def merge(ids, pair, new_id):
"""Replaces all occurrences of 'pair' with 'new_id' in the corpus."""
new_ids = []
i = 0
while i < len(ids):
if i < len(ids) - 1 and (ids[i], ids[i+1]) == pair:
new_ids.append(new_id)
i += 2
else:
new_ids.append(ids[i])
i += 1
return tuple(new_ids)
# --- Training Setup ---
corpus = "hug pug pun bun"
# Initial step: Split corpus into words and convert to byte sequences
# We use a frequency dictionary to speed up processing of large corpora
words = corpus.split()
counts = {tuple(word.encode("utf-8")): 1 for word in words}
num_merges = 5
merges = {} # (int, int) -> int
vocab = {i: bytes([i]) for i in range(256)} # Base byte vocabulary
print(f"Initial counts: {counts}\n")
# --- Core BPE Loop ---
for i in range(num_merges):
stats = get_stats(ids=None, counts=counts)
if not stats:
break
# 1. Find the most frequent pair
top_pair = max(stats, key=stats.get)
new_token_id = 256 + i
# 2. Record the merge
merges[top_pair] = new_token_id
# 3. Update the vocabulary
vocab[new_token_id] = vocab[top_pair[0]] + vocab[top_pair[1]]
# 4. Update the corpus counts with the new merged token
new_counts = {}
for word_ids, freq in counts.items():
new_word_ids = merge(word_ids, top_pair, new_token_id)
new_counts[new_word_ids] = freq
counts = new_counts
print(f"Merge {i+1}: {top_pair} -> {new_token_id} ({vocab[new_token_id].decode('utf-8', errors='replace')})")
print("\n--- Final Results ---")
print(f"Merge Table: {merges}")
print(f"Sample Word State: {list(counts.keys())[0]}")
# Output:
"""
Initial counts: {(104, 117, 103): 1, (112, 117, 103): 1, (112, 117, 110): 1, (98, 117, 110): 1}
Merge 1: (117, 103) -> 256 (ug)
Merge 2: (117, 110) -> 257 (un)
Merge 3: (104, 256) -> 258 (hug)
Merge 4: (112, 256) -> 259 (pug)
Merge 5: (112, 257) -> 260 (pun)
--- Final Results ---
Merge Table: {(117, 103): 256, (117, 110): 257, (104, 256): 258, (112, 256): 259, (112, 257): 260}
Sample Word State: (258,)
"""Why Subwords Strike the Right Balance
BPE’s subword vocabulary elegantly resolves the tension between character-level and word-level tokenization. Word-level tokenizers fail on rare or unseen words—they simply break at runtime, as there’s no representation for novel terms. Character-level tokenizers handle any input but produce excessively long sequences, inflating computational cost and making it harder for models to capture long-range dependencies. BPE finds a middle ground: common words like the get a single token, while rare words like defenestration decompose into meaningful subword units (def, en, est, ration) that the model can still reason about compositionally.
# tokenization output for common vs. rare words
# Compare how "the", "running", and "defenestration" get tokenized using a trained BPE vocabulary
import tiktoken
def demonstrate_bpe(text_list):
# Load the GPT-4 tokenizer (cl100k_base)
enc = tiktoken.get_encoding("cl100k_base")
print(f"{'Word':<18} | {'Tokens':<22} | {'Subword Breakdown'}")
print("-" * 60)
for text in text_list:
# Encode the string into token IDs
tokens = enc.encode(text)
# Decode individual tokens to see how the word was "chopped"
# We use .decode() on each individual ID
breakdown = [enc.decode([t]) for t in tokens]
print(f"{text:<18} | {str(tokens):<22} | {breakdown}")
# The test subjects
words = ["the", "running", "defenestration"]
demonstrate_bpe(words)
"""
Output:
Word | Tokens | Subword Breakdown
------------------------------------------------------------
the | [1820] | ['the']
running | [28272] | ['running']
defenestration | [755, 268, 478, 2214] | ['def', 'en', 'est', 'ration']
"""From Training to Inference
A subtle but important distinction: the merge table is learned during training on a fixed corpus, but applied deterministically during inference. When encoding new text, the tokenizer applies merges in the exact priority order they were learned—greedily matching the highest-priority merge first. This means the tokenizer’s behavior is fully deterministic and reproducible, a property that matters enormously for debugging, evaluation, and reproducibility in production systems.
The vocabulary size itself is a critical hyperparameter. Too small, and sequences become long and expensive to process. Too large, and the embedding matrix bloats, rare tokens get insufficient training signal, and memory costs escalate. Most modern LLMs settle in the range of 32,000 to 128,000 tokens, a sweet spot discovered through extensive empirical tuning.
Understanding these mechanics isn’t just academic—it directly informs decisions around vocabulary sizing, multilingual support, domain adaptation, and even fine-tuning strategies where tokenizer-model alignment can make or break performance.
Byte-Level BPE in the Wild: How GPT-2, GPT-4, LLaMA, and Other LLMs Implement Tokenization
The transition from character-level or word-level tokenization to byte-level Byte Pair Encoding (BPE) wasn’t merely academic but a practical engineering decision driven by the need to handle arbitrary text, including multilingual content, code, and edge-case Unicode characters, without an exploding vocabulary size. Understanding how production LLMs implement this algorithm reveals important design trade-offs that directly impact model performance, training efficiency, and downstream behavior.
GPT-2: The Byte-Level BPE Pioneer
OpenAI’s GPT-2 popularized byte-level BPE by operating directly on raw byte sequences rather than Unicode code points. The core insight: by starting with a base vocabulary of 256 byte tokens (representing every possible byte value), the tokenizer can encode any input string without ever producing an unknown token. GPT-2 then applies BPE merges learned from training data to iteratively combine frequent byte pairs into larger subword units, ultimately building a vocabulary of approximately 50,257 tokens.
Critically, GPT-2 introduced a regex-based pre-tokenization step before applying BPE merges. This pattern splits input text into coarse chunks—separating words, numbers, and punctuation—so that merges never cross word boundaries. The regex pattern used is:
# GPT-2 pre-tokenization regex pattern
import regex
pat = regex.compile(r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+""")This prevents pathological merges (e.g., merging the end of one word with the beginning of another) and ensures more linguistically coherent tokens.
GPT-4 and the cl100k_base Tokenizer
GPT-4 uses the cl100k_base tokenizer via OpenAI’s tiktoken library, expanding the vocabulary to ~100,000 tokens. The larger vocabulary reduces average sequence length—meaning fewer tokens per input—which directly translates to computational savings during attention computation (which scales quadratically with sequence length). The cl100k_base tokenizer also refines the pre-tokenization regex to better handle whitespace, code syntax, and multilingual text.
LLaMA and SentencePiece-Based BPE
Meta’s LLaMA family takes a different implementation path. Rather than using a custom tokenizer like tiktoken, LLaMA relies on SentencePiece, which implements BPE at the byte level with a unigram-aware training objective. LLaMA’s tokenizer uses a vocabulary of 32,000 tokens—significantly smaller than GPT-4’s—which keeps the embedding matrix compact but increases average sequence length. LLaMA also treats whitespace as explicit characters (using the ▁ marker), which preserves spacing information that byte-level approaches can otherwise obscure.
Key Implementation Differences
| Model | Library | Vocab Size | Pre-tokenization | Base Unit |
|---|---|---|---|---|
| GPT-2 | tiktoken / custom | ~50K | Regex split | Bytes |
| GPT-4 | tiktoken (cl100k_base) | ~100K | Refined regex | Bytes |
| LLaMA | SentencePiece | ~32K | Whitespace-aware | Bytes (via SentencePiece) |
These differences matter in practice. A smaller vocabulary means a smaller embedding layer and fewer parameters, but longer token sequences. A larger vocabulary compresses text more aggressively but increases memory footprint. When fine-tuning or adapting these models, vocabulary mismatch between your data distribution and the pretrained tokenizer’s merge priorities can degrade performance—rare domain-specific terms may fragment into many small tokens, reducing the model’s effective context window.
The Shared Foundation
Despite implementation differences, all of these models share the same foundational BPE principle: start with bytes as atomic units, count pair frequencies across the training corpus, merge the most frequent pair, and repeat. The text is first converted into a byte array—every character mapped to one or more bytes depending on its UTF-8 encoding—and the learned merge table is then applied greedily at inference time. This guarantees complete coverage of any input without out-of-vocabulary failures, a property that word-level and even many character-level tokenizers cannot offer.
For engineers building on these models, the practical takeaway is clear: tokenization is not a preprocessing afterthought. It is an architectural decision with measurable downstream consequences on context utilization, training cost, and multilingual robustness.
Limitations of BPE and Emerging Alternatives: WordPiece, Unigram, SentencePiece, and LBPE
While Byte Pair Encoding remains the dominant subword tokenization algorithm powering models like GPT-2, GPT-4, and LLaMA, it carries inherent limitations that practitioners must understand—especially when selecting or customizing a tokenizer for production systems. These limitations have spurred the development of several alternatives, each addressing specific shortcomings in BPE’s design.
Where BPE Falls Short
BPE’s greedy, frequency-based merge strategy is both its strength and its weakness. The algorithm iteratively merges the most frequent adjacent byte or character pairs, building a vocabulary bottom-up. However, this deterministic, greedy approach introduces several problems:
- Suboptimal segmentation: Because BPE commits to merges based purely on local frequency counts, it can produce tokenizations that are globally suboptimal. A merge that seems beneficial early in training may fragment semantically meaningful subwords later.
- Lack of probabilistic reasoning: BPE assigns no probability to its segmentations. It produces exactly one tokenization for any given input, ignoring the possibility that alternative segmentations might better capture morphological or semantic structure.
- Vocabulary rigidity: Once the merge table is learned, BPE applies it deterministically. This means rare or domain-specific terms—common in scientific, medical, or legal text—often get fragmented into unintuitive subword sequences, degrading downstream model performance.
- Language and script bias: BPE vocabularies trained predominantly on English or Latin-script text allocate disproportionate vocabulary capacity to those languages, leaving non-Latin scripts (CJK, Devanagari, Arabic) with poor token efficiency and inflated sequence lengths.
These constraints matter significantly when you’re fine-tuning LLMs on specialized corpora or building multilingual systems where tokenization quality directly impacts training compute and inference latency.
WordPiece and Unigram: Probabilistic Alternatives
WordPiece, used in BERT and its derivatives, resembles BPE structurally but differs in its merge criterion. Instead of selecting the most frequent pair, WordPiece merges the pair that maximizes the likelihood of the training corpus under a language model. This probabilistic grounding produces vocabularies that better capture the statistical structure of the data, though at higher computational cost during vocabulary construction.
Unigram Language Model tokenization, proposed by Kudo (2018), takes the opposite approach entirely. It starts with a large initial vocabulary and prunes it iteratively, removing tokens whose loss contributes least to the overall corpus likelihood. Crucially, Unigram can sample from multiple valid segmentations during training—a form of subword regularization that acts as data augmentation and improves model robustness to morphological variation.
SentencePiece: Unifying the Pipeline
SentencePiece addresses a different but equally important limitation: preprocessing dependency. Traditional BPE implementations, including the one popularized by Sennrich et al. and adapted at the byte level in the GPT-2 paper, assume pre-tokenized (whitespace-split) input. SentencePiece treats the input as a raw byte or Unicode stream, eliminating language-specific pre-tokenization rules. It supports both BPE and Unigram as backend algorithms, making it a versatile, language-agnostic framework used in models like T5 and ALBERT.
LBPE: Pushing Byte-Level Boundaries
Byte-Level BPE (BBPE) and its extensions like LBPE (Learned Byte Pair Encoding) operate directly on raw bytes rather than Unicode characters, guaranteeing complete coverage of any input without unknown tokens. GPT-2 pioneered this byte-level adaptation, and subsequent work has focused on improving its efficiency—particularly reducing the sequence length inflation that byte-level operation causes for multibyte scripts. LBPE variants explore learned merge priorities and hybrid strategies that balance the universality of byte-level operation with the compactness of character-aware tokenization.
A Comparative Analysis of Subword Tokenization Methods: arxiv link
Choosing the Right Tokenizer
No single tokenizer dominates across all axes. BPE offers simplicity and proven performance at scale. WordPiece provides better statistical grounding. Unigram enables subword regularization. SentencePiece removes preprocessing assumptions. The right choice depends on your language distribution, vocabulary budget, and whether you prioritize training robustness or inference determinism. For engineers building or fine-tuning LLMs, understanding these trade-offs is not optional—it directly shapes model quality, efficiency, and multilingual capability.
The Critical Role of BPE in Shaping LLM Performance and What Comes Next
Byte Pair Encoding has proven itself as far more than a preprocessing convenience—it is a foundational algorithmic choice that directly shapes the performance, generalization capability, and computational efficiency of modern large language models. From GPT-family models to LLaMA and beyond, BPE remains the dominant subword tokenization strategy, and understanding why it works so well is essential for any practitioner building, fine-tuning, or optimizing LLMs.
Why BPE Endures
At its core, BPE solves a fundamental tension in NLP: the trade-off between vocabulary coverage and representation efficiency. Character-level tokenization produces tiny vocabularies but generates excessively long sequences that strain attention mechanisms. Word-level tokenization keeps sequences short but breaks catastrophically on unseen or rare words—any out-of-vocabulary token becomes meaningless at runtime. BPE navigates this trade-off by iteratively merging the most frequent byte pairs to construct a subword vocabulary that captures common morphological patterns while gracefully decomposing rare words into meaningful subunits.
This property has concrete downstream consequences. A well-trained BPE vocabulary ensures that:
- Common words are represented as single tokens, preserving computational efficiency during training and inference.
- Rare or novel words decompose into recognizable subword units, enabling the model to leverage compositional semantics rather than discarding unknown inputs.
- Multilingual and code-mixed text can be handled without separate preprocessing pipelines, since byte-level BPE operates on raw byte sequences regardless of script or encoding.
The byte-level foundation is critical here. Because BPE can operate directly on a byte array representation of text, it inherently supports any UTF-8 encoded input. There is no concept of an “unknown” token—every possible input can be decomposed into bytes, and the merge table reconstructs higher-order tokens from there.
The Performance Implications of Tokenizer Design
For ML engineers fine-tuning or training LLMs, tokenizer choice is not a set-and-forget decision. The BPE vocabulary size, the training corpus used to learn merges, and the merge order all influence model behavior in measurable ways. A tokenizer trained on English-dominant corpora will fragment non-English text into far more tokens per sentence, increasing sequence length, inflating compute costs, and degrading model quality for those languages. Similarly, domain-specific fine-tuning—on legal text, biomedical literature, or source code—often benefits from retraining or extending the BPE vocabulary to capture domain-specific subword patterns that the base tokenizer underrepresents.
What Comes Next
Despite its dominance, BPE is not without limitations. Its greedy, frequency-based merge strategy is deterministic and does not account for downstream task performance during vocabulary construction. Several active research directions aim to address this:
- Unigram Language Model tokenization (used in SentencePiece) takes a probabilistic approach, starting with a large vocabulary and pruning based on likelihood—offering a principled alternative to BPE’s bottom-up merging.
- Tokenizer-free architectures such as ByT5 and MegaByte explore operating directly on raw bytes or byte patches, eliminating the tokenization step entirely and sidestepping vocabulary mismatch issues.
- Dynamic or adaptive tokenization methods investigate adjusting the vocabulary at fine-tuning time or even at inference time, tailoring subword segmentation to the input distribution.
- Multimodal tokenization extends the concept beyond text, unifying text, image patches, and audio frames under a shared discrete token space.
However, none of these approaches have yet displaced BPE at scale. The algorithm’s simplicity, determinism, and well-understood behavior make it a reliable default. For practitioners today, the actionable takeaway is clear: invest time in understanding and auditing your tokenizer. Inspect how your BPE vocabulary segments domain-specific inputs. Profile the token-per-word ratio across your target languages. Consider whether vocabulary extension or retraining is warranted before committing GPU hours to model training.
BPE may eventually yield to more sophisticated tokenization paradigms, but its influence on the architecture and training dynamics of modern LLMs is indelible. Mastering it remains a non-negotiable skill for anyone serious about building performant language models.
Frequently Asked Questions
Q: What is Byte Pair Encoding (BPE) in large language models?
A: Byte Pair Encoding is a subword tokenization algorithm that iteratively merges the most frequent pairs of characters or character sequences in a text corpus to build a fixed-size vocabulary. It allows LLMs like GPT to represent any text—including rare and unseen words—as a sequence of known subword tokens, balancing vocabulary size with representation efficiency.
Q: Why do LLMs use subword tokenization instead of word-level or character-level tokenization?
A: Word-level tokenization creates enormous vocabularies and cannot handle out-of-vocabulary words, while character-level tokenization produces excessively long sequences that are computationally expensive. Subword tokenization methods like BPE strike an optimal balance by representing common words as single tokens and breaking rare words into meaningful subword units.
Q: What is the difference between WordPiece and BPE tokenization?
A: Both are subword tokenization algorithms, but they differ in how they select merges. BPE merges the most frequent pair of adjacent tokens at each step, while WordPiece selects the pair that maximizes the likelihood of the training corpus when merged. WordPiece is used in models like BERT, whereas BPE is the foundation for GPT-series tokenizers.
Q: How does the BPE algorithm build its token vocabulary?
A: BPE starts with a base vocabulary of individual characters (or bytes) and then repeatedly scans the training corpus to find the most frequently co-occurring adjacent pair of tokens. That pair is merged into a single new token and added to the vocabulary. This process repeats until the desired vocabulary size is reached.
Q: What is SentencePiece and how does it relate to BPE?
A: SentencePiece is a language-independent tokenization library developed by Google that can implement both BPE and unigram language model tokenization. It operates directly on raw text without requiring pre-tokenization or whitespace splitting, making it especially useful for multilingual LLMs and languages without clear word boundaries.